Archivsoftware
Liebe Kolleginnen und Kollegen,
zur Vorbereitung eines Workshop auf der Konferenz "Offene Archive 2.2" bitte ich Sie als Archivarinnen und Archivare, den verlinkten kurzen Fragebogen über Ihre Vorstellungen hinsichtlich einer zeitgemäßen Erschließungssoftware auszufüllen.
Ich bitte zugleich dringend darum, den Fragebogen nicht auszufüllen, falls Sie nicht als Archivar(in), FAMI oder in archivarischer Funktion, sondern "nur" als Archivnutzer(in) tätig sind. Für Archivnutzer wird es einen eigenen Fragebogen geben. Beide korrespondieren miteinander. Sie können den Bogen gerne an Kollegen weiterverteilen.
https://ubayreuthmarketing.qualtrics.com/SE/?SID=SV_3z0CrmnCOeMgi7r
zur Vorbereitung eines Workshop auf der Konferenz "Offene Archive 2.2" bitte ich Sie als Archivarinnen und Archivare, den verlinkten kurzen Fragebogen über Ihre Vorstellungen hinsichtlich einer zeitgemäßen Erschließungssoftware auszufüllen.
Ich bitte zugleich dringend darum, den Fragebogen nicht auszufüllen, falls Sie nicht als Archivar(in), FAMI oder in archivarischer Funktion, sondern "nur" als Archivnutzer(in) tätig sind. Für Archivnutzer wird es einen eigenen Fragebogen geben. Beide korrespondieren miteinander. Sie können den Bogen gerne an Kollegen weiterverteilen.
https://ubayreuthmarketing.qualtrics.com/SE/?SID=SV_3z0CrmnCOeMgi7r
Kühnel Karsten - am Freitag, 3. Juli 2015, 15:46 - Rubrik: Archivsoftware
Falls
http://www.noela.findbuch.net/php/view2.php?ar_id=3695&be_id=505&ve_id=2350098&count=
nicht (oder nach einer Weile nicht mehr) funktioniert:
http://www.noela.findbuch.net/
Links: Sammlungen und Nachlässe anklicken.
Links: 05.03 Handschriftensammlungen anklicken
Rechts: HS StA anklicken
Rechts: Liste der Verzeichnungseinheiten anklicken
Rechts: Trenbach Chronik anklicken
Rechts: Schieberegler zum Herunterscrollen suchen.
Herunterscrollen und auf "zu den Bildern" klicken.
***
http://frueheneuzeit.hypotheses.org/1847 steht jetzt übrigens unter einer CC-BY-Lizenz
http://www.noela.findbuch.net/php/view2.php?ar_id=3695&be_id=505&ve_id=2350098&count=
nicht (oder nach einer Weile nicht mehr) funktioniert:
http://www.noela.findbuch.net/
Links: Sammlungen und Nachlässe anklicken.
Links: 05.03 Handschriftensammlungen anklicken
Rechts: HS StA anklicken
Rechts: Liste der Verzeichnungseinheiten anklicken
Rechts: Trenbach Chronik anklicken
Rechts: Schieberegler zum Herunterscrollen suchen.
Herunterscrollen und auf "zu den Bildern" klicken.
***
http://frueheneuzeit.hypotheses.org/1847 steht jetzt übrigens unter einer CC-BY-Lizenz
KlausGraf - am Mittwoch, 11. Februar 2015, 17:00 - Rubrik: Archivsoftware
Gesehen beim NÖLA, wo ich in letzter Zeit virtuell häufig war. Das Stadtarchiv Speyer bietet noch den alten Viewer, den ich gar nicht mochte. Aber nun kommt er mir fast schon OK vor ...
KlausGraf - am Dienstag, 10. Februar 2015, 21:03 - Rubrik: Archivsoftware
noch kein Kommentar - Kommentar verfassen
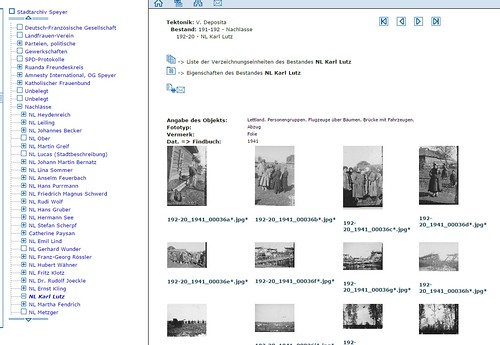
http://kriegsfoto.hypotheses.org/637 meldet, dass 4000 Fotos von Karl Lutz im Speyerer Findbuch.net abrufbar seien.
Schon beim NÖ Landesarchiv hatte ich Probleme mit der Bildschirmdarstellung.
http://archiv.twoday.net/stories/1022387562/
Im Fall von Speyer stellte sich heraus, dass ich erst das Chrome-Browserfenster verkleinern musste, um an den Schieberegler für die unteren Bilder zu kommen. Eigenartigerweise zeigt Windows Snipping Tool den Bildschirm mit der Scrollmöglichkeit, während der Screenshot über die Taste "Druck" den wahren Stand wiedergibt. Habe ich irgendetwas falsch eingestellt oder ist die Software einfach erdenschlecht?
Ich habe
http://www.stadtarchiv-speyer.findbuch.net/php/main.php?ar_id=3723&be_kurz=3139322d3230&ve_vnum=0#3139322d3230x36 (führt nur zum Bestand)
und dann den ersten Eintrag der Liste zu Lettland auch mit dem Internet-Explorer getestet. Wie bei Chrome funktionierten die Pfeiltasten und "Seite nach unten" NICHT. Aber der Schieberegler war von Anfang an benutzbar. Bei FF gingen Pfeiltaste/Seite nach unten, aber für den Schieberegler musste erst wie bei Chrome verkleinert werden.
Hier einige weitere Kritikpunkte am Findbuch.net der Firma AUGIAS:
* Die Optik ist in den 1990ern stehengeblieben. Findbuch.net sieht einfach scheusslich aus.
* Von einer intuitiv leichten Benutzbarkeit von Findbuch.net kann keine Rede sein.
* Es gibt keine Permalinks (mit dem man sich z.B. auf eine Bildserie oder ein Einzelbild beziehen könnte).
* Der Viewer ist langsam, proprietär und hässlich. Leider wird er auch in Monasterium.net eingesetzt, wo er häufig nicht funktioniert. Der komplette Verzeichnungseintrag rechts oben ist nicht lesbar. Rechts gibt es einen Schieberegler (Kreis), dessen Funktion mir nicht klar ist.
Usw.
Schon beim NÖ Landesarchiv hatte ich Probleme mit der Bildschirmdarstellung.
http://archiv.twoday.net/stories/1022387562/
Im Fall von Speyer stellte sich heraus, dass ich erst das Chrome-Browserfenster verkleinern musste, um an den Schieberegler für die unteren Bilder zu kommen. Eigenartigerweise zeigt Windows Snipping Tool den Bildschirm mit der Scrollmöglichkeit, während der Screenshot über die Taste "Druck" den wahren Stand wiedergibt. Habe ich irgendetwas falsch eingestellt oder ist die Software einfach erdenschlecht?
Ich habe
http://www.stadtarchiv-speyer.findbuch.net/php/main.php?ar_id=3723&be_kurz=3139322d3230&ve_vnum=0#3139322d3230x36 (führt nur zum Bestand)
und dann den ersten Eintrag der Liste zu Lettland auch mit dem Internet-Explorer getestet. Wie bei Chrome funktionierten die Pfeiltasten und "Seite nach unten" NICHT. Aber der Schieberegler war von Anfang an benutzbar. Bei FF gingen Pfeiltaste/Seite nach unten, aber für den Schieberegler musste erst wie bei Chrome verkleinert werden.
Hier einige weitere Kritikpunkte am Findbuch.net der Firma AUGIAS:
* Die Optik ist in den 1990ern stehengeblieben. Findbuch.net sieht einfach scheusslich aus.
* Von einer intuitiv leichten Benutzbarkeit von Findbuch.net kann keine Rede sein.
* Es gibt keine Permalinks (mit dem man sich z.B. auf eine Bildserie oder ein Einzelbild beziehen könnte).
* Der Viewer ist langsam, proprietär und hässlich. Leider wird er auch in Monasterium.net eingesetzt, wo er häufig nicht funktioniert. Der komplette Verzeichnungseintrag rechts oben ist nicht lesbar. Rechts gibt es einen Schieberegler (Kreis), dessen Funktion mir nicht klar ist.
Usw.
KlausGraf - am Montag, 19. Januar 2015, 17:32 - Rubrik: Archivsoftware
Archiverschließung und -verwaltung mit standardkonformer Software
Geschrieben für die Softwareanbieter der Archivistica 2013 ;-)
Geschrieben für die Softwareanbieter der Archivistica 2013 ;-)
Kühnel Karsten - am Donnerstag, 5. September 2013, 09:10 - Rubrik: Archivsoftware
noch kein Kommentar - Kommentar verfassen
KlausGraf - am Freitag, 8. Februar 2013, 16:40 - Rubrik: Archivsoftware
noch kein Kommentar - Kommentar verfassen
Das Firefox-Skript http://jk.g6.cz/dezoomify.html ermöglicht das Herunterladen eines kompletten Bildes einer Zoomify-Anwendung.
Siehe auch
http://de.wikisource.org/wiki/Benutzer:Paulis/Zoomify
Siehe auch
http://de.wikisource.org/wiki/Benutzer:Paulis/Zoomify
KlausGraf - am Sonntag, 30. Dezember 2012, 20:43 - Rubrik: Archivsoftware
noch kein Kommentar - Kommentar verfassen
http://hdl.handle.net/2027/mdp.39015072446613?urlappend=%3Bseq=239
Siehe auch
http://archiv.twoday.net/search?q=sachav
Siehe auch
http://archiv.twoday.net/search?q=sachav
KlausGraf - am Dienstag, 23. Oktober 2012, 19:02 - Rubrik: Archivsoftware
Als Dienstleister kann man den Verdacht, stets auch immer werben zu wollen, grundsätzlich nicht ausräumen. Nachfolgender Beitrag behandelt aber OpenSource-Software-Bausteine, die wir mit der archium UG zwar wohl als erste in dieser Form eingesetzt haben, nichtsdestotrotz unterliegen sie einer "OpenSource"-Lizenz und sind somit auch unabhängig von uns zu beziehen und zu nutzen. Insofern möge man mir den kurzen Hinweis auf das Unternehmen als "Vorgeschichte" nachsehen.
Interessieren dürfte der Beitrag möglicherweise so manchen Archivaren mit gewissem Drang zur Unabhängigkeit.
Vorgeschichte
Die Essinger Firma archium betreut eine Anzahl von Unternehmensarchiven in Süddeutschland und betreibt Softwareprojekte rund um die Archivierung.
Bereits ab 2008 favorisierten wir die Verwendung einer OpenSource-Erschließungssoftware. ICA-AtoM erschien uns damals als geradezu ideal konzipiert, es erwies sich aber im laufenden Betrieb als mangelhaft umgesetzt. Um unseren Kunden dennoch eine OpenSource-Archivsoftware bieten zu können, haben wir ab Ende 2010 einen recht unkonventionellen Weg beschritten. Wir haben die sehr bewährte OpenSource-Software, die wir zuvor schon seit vielen Jahren für das Projektmanagement genutzt hatten, für den Einsatz im Archiv ausgebaut: Das MediaWiki. Mittlerweile ist es bei mehreren von uns betreuten Unternehmensarchiven im Einsatz.
Aber warum denn unbedingt OpenSource?
"OpenSource" bietet einen fundamentalen Vorzug für Archive.
Eigentlich kann keine Software für sich in Anspruch nehmen, wirklich langzeitstabil zu sein. Software lebt von der Weiterentwicklung. Eine Software, die nicht kontinuierlich gepflegt wird, ist angezählt und nach kurzer Zeit nicht mehr einsetzbar. Denn die Betriebssysteme, Formate, Applikationen und ganz besonders auch die Code-Libraries entwickeln sich drumherum ständig weiter und warten nicht, wenn ein einzelnes Programm aus ihren Reihen zurückbleibt. Auch im Archiv spielen wir dieses Spiel zwangsläufig mit und hoffen, daß der Software-Dealer, der uns den Stoff verkauft hat, dies möglichst lange weiter tun wird und zwar zu gleichbleibenden Konditionen.
OpenSource-Anwender hängen an dieser Nadel nicht. Dabei bietet OpenSource-Software schon grundsätzlich eine bessere Zukunftsprognose. Eine Software, deren Codes vollständig offengelegt sind, gibt die technische Gewähr dafür, daß die Programme prinzipiell weiterentwickelt werden können, selbst wenn der Anbieter nicht mehr existiert oder die Entwicklung einstellt. Und Software, die unter einer freien Lizenz herausgegeben wird, gibt eine ökonomische Gewähr, daß regelmäßige Lizenzkosten entfallen und Wartungskosten auch auf lange Sicht überschaubar bleiben.
Starke Verbreitung des MediaWiki
Allein schon aus diesen Gründen mußte sich eine MediaWiki-Installation wunderbar eignen für den Betrieb in Archiven und Sammlungen. Doch das MediaWiki kann mehr, viel mehr. Es begegnet uns täglich in etlichen tausend Installationen im Internet, gelegentlich zweckentfremdet als CMS gebraucht, zumeist aber als leistungsfähige Basis für Multi-Autorenprojekte. Das prominenteste ist zweifellos die Wikipedia. 1,4 Millionen Datensätze umfasst gegenwärtig allein deren deutscher Zweig. Und diese sehr gut skalierbare Software stöhnt unter dieser Datenlast nicht ansatzweise. Die Zahl der aktiven Benutzer ist jedenfalls jetzt schon so groß, daß der Fortbestand dieser Software sehr eng verflochten sein wird mit dem Fortbestand des freien Internets überhaupt. Denn selbst wenn die Entwicklung der Software MediaWiki eines Tages eingestellt würde, so gäbe es viele tausend Argumente dafür, eine alternative Software zu entwickeln, die ihre Datensätze lesen kann.
Das Lesen der Datensätze -- oder besser als »pages« wahrgenommen -- ist übrigens sehr einfach. MediaWiki speichert Informationen für den Anwender in reiner Textform. Im Hintergrund aber erstellt es einen ObjektCache. Dadurch sind die Daten für den Menschen einerseits mit relativ einfachen Software-Werkzeugen lesbar und zu bearbeiten, der ObjektCache im Hintergrund aber sorgt für die Performance der Maschine, also dafür, daß Recherchen über große Datenbestände schnell zu einem Resultat führen.
Eine »Extension«, die MediaWiki zur Datenbank macht
Auf diese Weise wären wir zunächst aber nur in der Lage, eine strukturierte Textsammlung zu führen. Durch das MediaWiki-eigene Kategoriesystem, über welches sich in der Wikipedia die Zuordnung der Artikel zu Jahrestagen und Personengruppen umsetzen lassen, ist es nun zwar möglich, Indizes zu führen, eine echte Datenbank haben wir damit aber noch nicht. Hier hilft eine der zahlreichen MediaWiki-Erweiterungen, eine s.g. »Extension«, die beim KIT-Karlsruhe im Institut für Angewandte Informatik und Formale Beschreibungsverfahren (AIFB) entwickelt wurde, das »Semantic MediaWiki«.
Durch die Semantic MediaWiki-Extension wird es möglich, im Text des MediaWiki Felder mit festgesetzten Typen zu definieren und Werte zuzuweisen. Gleichzeitig bleiben die zahlreichen Gestaltungsmittel des MediaWiki verfügbar und können in den Inhalt dieser Felder integriert werden. Diesen, in der deutschen Version »Attribute« und in der englischen Fassung »property« genannten, Feldern sind vielfältige Datentypen zuzordnen. z.B. Volltext, Zeichenkette, Datum, Zahl, URL uvm.
Weitere Extensions erweitern das System um die Möglichkeit der Formulareingabe, stellen eine eigene Parsersprache bereit und erlauben Zeichenkettenoperationen. Das MediaWiki wird damit zu einem äußerst vielseitigen und universell konfigurierbaren Datenbankbaukasten. Wie in jeder anderen Datenbank auch können die Inhalte nun über logische Abfragen erschlossen werden. Die Ergebnismengen enthalten die relevanten »pages«, deren Inhalte aber auch in Tabellenform oder vielen anderen Austauschformaten ausgegeben werden können. Der Datenaustausch erfolgt beispielsweise über XML oder CSV, ermöglicht eigene Volltextfilter und PDF-Ausdrucke.
Die Einrichtung (oder zu Deutsch das »Customizing«) der Datenbank erfolgt über eine Kaskade miteinander verknüpfter Makros, welche die Benutzereingaben interpretieren. Die Funktionsweise läßt sich mit dem geschichteten Aufbau der Erdkugel vergleichen. Der Benutzer bewegt sich auf der Erdkruste. Hier erfolgen die Eingaben. Diese werden über Makros im Oberen Erdmantel in den Unteren Erdmantel geleitet. Dort werden den »properties« die Werte zugewiesen. Und bis hierher kann der Benutzer -- entsprechende Administratorrechte vorausgesetzt -- noch über die Browser-Oberfläche selbst zugreifen. Der Erdkern darunter ist mit PHP- und SQL-Kenntnissen zu erschließen. Im äußeren Erdkern werden die zahlreichen Extensions installiert, die den Inneren Erdkern um zahlreiche Funktionalitäten erweitern.
Diese Analogie zu Ende spinnend: Erdbeben erfolgen ausnahmslos an der Oberfläche, der harte Kern ist sehr stabil bzw. ausgereift. Doch anders als das Erd-Modell verfügt das MediaWiki über eine Versionsgeschichte, die sämtliche Änderungen der Benutzer reversibel macht. Fehleingaben werden dadurch leicht verziehen. Außerdem bleiben alte Zustände dadurch zitierfähig.
Die Möglichkeit zur Rekonstruktion alter Stände gilt übrigens nicht nur für Textinhalte. Auch Dateien können versioniert gespeichert werden. Und wie aus der Wikipedia bekannt, können Bildformate direkt sichtbar gemacht werden. Auf diese Weise läßt sich das MediaWiki ohne weiteres zur Bilddatenbank und zu einem Dokumentenmanagement erweitern.
Für die diesem Aufsatz zugrunde liegende Musterdatenbank wurde ein Datenmodell gewählt, das dem ISAD(G)-Standard sehr nahe kommt. Kleine Abweichungen sind im zusätzlichen »Darin«-Feld zu erkennen. Auch die Bilder oder Anhänge sind untypisch, zeigen aber den fließenden Übergang zur Bilddatenbank.
Die große Stärke des MediaWiki zeigt sich gerade dann, wenn es gilt, Datenmodelle (u. U. im laufenden Betrieb) umzubauen. Der Umstand, daß auf der »Erdkruste« und im »Erdmantel« Code und Daten miteinander verschmelzen, ermöglicht die Durchführung systemrelevanter Änderungen mit Textwerkzeugen, die sämtlich das MediaWiki selbst anbietet! So ist es problemlos möglich, Änderungen an einer großen Anzahl von Datensätzen global vorzunehmen.
Schwächen?
Bei allem Lob, es gibt natürlich auch Schwächen.
Es kann vorkommen, daß der ObjektCache im Erdkern der Aktivität im Erdmantel hinterherhinkt. Normalerweise wird dies nur nach automatisierten Schreib-Lese-Vorgängen großer Datenmengen sichtbar, weshalb die Beeinträchtigungen eher den Administrator treffen, und nicht den Anwender. Es existieren aber Hilfsmittel, um das Abarbeiten der s.g. »Job Queue« zu beschleunigen und Ansichten zu aktualisieren.
Das MediaWiki bietet einen solch reichen Kosmos an Möglichkeiten, daß dem Bearbeiter unweigerlich mehr Sachverstand abverlangt wird. Immerhin ist diese Anforderung nicht sehr speziell, schließlich bringt jeder, der sich schon an der Wikipedia beteiligt hat, diese Kenntnisse mit. Außerdem sind die Arbeitsprozesse bestens dokumentiert. Trotzdem muß der Bearbeiter die Tektonik seines Archivs kennen und z.B. bei der Vergabe von Signaturen diszipliniert arbeiten. Diese potentielle Fehlerquelle wird allerdings sehr schön dadurch kompensiert, daß in Serie eingeschlichene Fehler eines unerfahrenen Bearbeiters in der Regel über ein umfassendes Suchen&Ersetzen leicht behoben werden können. Auf dieselbe Weise lassen sich übrigens auch neue Vorgaben problemlos auf ältere Datensätze anwenden, ohne daß ein erneutes Aufrufen alter Datensätze notwendig werden würde.
Fazit
Zusammenfassend ist zu sagen: Das Potential des zur Datenbank gereiften MediaWiki ist enorm! Schon die Performance ist überzeugend und die Kinderkrankheiten sind bei einer Software mit solch großer Verbreitung weitestgehend ausgeheilt. Und prinzipiell kann kein proprietäres System hinsichtlich Langzeitarchivierung bieten, was ein OpenSource-System wie das MediaWiki bietet: Eine sehr günstige Zukunftsprognose, Bindungsfreiheit, die denkbar geringsten Anschaffungskosten und eine sehr gut kalkulierbare Kostenentwicklung im laufenden Betrieb.
Die Musterdatenbank der hier gezeigten Beispiele ist online einsehbar hier.
Der identische Aufsatz ist auch als PDF verfügbar hier.
Interessieren dürfte der Beitrag möglicherweise so manchen Archivaren mit gewissem Drang zur Unabhängigkeit.
Vorgeschichte
Die Essinger Firma archium betreut eine Anzahl von Unternehmensarchiven in Süddeutschland und betreibt Softwareprojekte rund um die Archivierung.
Bereits ab 2008 favorisierten wir die Verwendung einer OpenSource-Erschließungssoftware. ICA-AtoM erschien uns damals als geradezu ideal konzipiert, es erwies sich aber im laufenden Betrieb als mangelhaft umgesetzt. Um unseren Kunden dennoch eine OpenSource-Archivsoftware bieten zu können, haben wir ab Ende 2010 einen recht unkonventionellen Weg beschritten. Wir haben die sehr bewährte OpenSource-Software, die wir zuvor schon seit vielen Jahren für das Projektmanagement genutzt hatten, für den Einsatz im Archiv ausgebaut: Das MediaWiki. Mittlerweile ist es bei mehreren von uns betreuten Unternehmensarchiven im Einsatz.
Aber warum denn unbedingt OpenSource?
"OpenSource" bietet einen fundamentalen Vorzug für Archive.
Eigentlich kann keine Software für sich in Anspruch nehmen, wirklich langzeitstabil zu sein. Software lebt von der Weiterentwicklung. Eine Software, die nicht kontinuierlich gepflegt wird, ist angezählt und nach kurzer Zeit nicht mehr einsetzbar. Denn die Betriebssysteme, Formate, Applikationen und ganz besonders auch die Code-Libraries entwickeln sich drumherum ständig weiter und warten nicht, wenn ein einzelnes Programm aus ihren Reihen zurückbleibt. Auch im Archiv spielen wir dieses Spiel zwangsläufig mit und hoffen, daß der Software-Dealer, der uns den Stoff verkauft hat, dies möglichst lange weiter tun wird und zwar zu gleichbleibenden Konditionen.
OpenSource-Anwender hängen an dieser Nadel nicht. Dabei bietet OpenSource-Software schon grundsätzlich eine bessere Zukunftsprognose. Eine Software, deren Codes vollständig offengelegt sind, gibt die technische Gewähr dafür, daß die Programme prinzipiell weiterentwickelt werden können, selbst wenn der Anbieter nicht mehr existiert oder die Entwicklung einstellt. Und Software, die unter einer freien Lizenz herausgegeben wird, gibt eine ökonomische Gewähr, daß regelmäßige Lizenzkosten entfallen und Wartungskosten auch auf lange Sicht überschaubar bleiben.
Starke Verbreitung des MediaWiki
Allein schon aus diesen Gründen mußte sich eine MediaWiki-Installation wunderbar eignen für den Betrieb in Archiven und Sammlungen. Doch das MediaWiki kann mehr, viel mehr. Es begegnet uns täglich in etlichen tausend Installationen im Internet, gelegentlich zweckentfremdet als CMS gebraucht, zumeist aber als leistungsfähige Basis für Multi-Autorenprojekte. Das prominenteste ist zweifellos die Wikipedia. 1,4 Millionen Datensätze umfasst gegenwärtig allein deren deutscher Zweig. Und diese sehr gut skalierbare Software stöhnt unter dieser Datenlast nicht ansatzweise. Die Zahl der aktiven Benutzer ist jedenfalls jetzt schon so groß, daß der Fortbestand dieser Software sehr eng verflochten sein wird mit dem Fortbestand des freien Internets überhaupt. Denn selbst wenn die Entwicklung der Software MediaWiki eines Tages eingestellt würde, so gäbe es viele tausend Argumente dafür, eine alternative Software zu entwickeln, die ihre Datensätze lesen kann.
|

Das Lesen der Datensätze -- oder besser als »pages« wahrgenommen -- ist übrigens sehr einfach. MediaWiki speichert Informationen für den Anwender in reiner Textform. Im Hintergrund aber erstellt es einen ObjektCache. Dadurch sind die Daten für den Menschen einerseits mit relativ einfachen Software-Werkzeugen lesbar und zu bearbeiten, der ObjektCache im Hintergrund aber sorgt für die Performance der Maschine, also dafür, daß Recherchen über große Datenbestände schnell zu einem Resultat führen.
Eine »Extension«, die MediaWiki zur Datenbank macht
Auf diese Weise wären wir zunächst aber nur in der Lage, eine strukturierte Textsammlung zu führen. Durch das MediaWiki-eigene Kategoriesystem, über welches sich in der Wikipedia die Zuordnung der Artikel zu Jahrestagen und Personengruppen umsetzen lassen, ist es nun zwar möglich, Indizes zu führen, eine echte Datenbank haben wir damit aber noch nicht. Hier hilft eine der zahlreichen MediaWiki-Erweiterungen, eine s.g. »Extension«, die beim KIT-Karlsruhe im Institut für Angewandte Informatik und Formale Beschreibungsverfahren (AIFB) entwickelt wurde, das »Semantic MediaWiki«.
|

Durch die Semantic MediaWiki-Extension wird es möglich, im Text des MediaWiki Felder mit festgesetzten Typen zu definieren und Werte zuzuweisen. Gleichzeitig bleiben die zahlreichen Gestaltungsmittel des MediaWiki verfügbar und können in den Inhalt dieser Felder integriert werden. Diesen, in der deutschen Version »Attribute« und in der englischen Fassung »property« genannten, Feldern sind vielfältige Datentypen zuzordnen. z.B. Volltext, Zeichenkette, Datum, Zahl, URL uvm.
|

Weitere Extensions erweitern das System um die Möglichkeit der Formulareingabe, stellen eine eigene Parsersprache bereit und erlauben Zeichenkettenoperationen. Das MediaWiki wird damit zu einem äußerst vielseitigen und universell konfigurierbaren Datenbankbaukasten. Wie in jeder anderen Datenbank auch können die Inhalte nun über logische Abfragen erschlossen werden. Die Ergebnismengen enthalten die relevanten »pages«, deren Inhalte aber auch in Tabellenform oder vielen anderen Austauschformaten ausgegeben werden können. Der Datenaustausch erfolgt beispielsweise über XML oder CSV, ermöglicht eigene Volltextfilter und PDF-Ausdrucke.
Die Einrichtung (oder zu Deutsch das »Customizing«) der Datenbank erfolgt über eine Kaskade miteinander verknüpfter Makros, welche die Benutzereingaben interpretieren. Die Funktionsweise läßt sich mit dem geschichteten Aufbau der Erdkugel vergleichen. Der Benutzer bewegt sich auf der Erdkruste. Hier erfolgen die Eingaben. Diese werden über Makros im Oberen Erdmantel in den Unteren Erdmantel geleitet. Dort werden den »properties« die Werte zugewiesen. Und bis hierher kann der Benutzer -- entsprechende Administratorrechte vorausgesetzt -- noch über die Browser-Oberfläche selbst zugreifen. Der Erdkern darunter ist mit PHP- und SQL-Kenntnissen zu erschließen. Im äußeren Erdkern werden die zahlreichen Extensions installiert, die den Inneren Erdkern um zahlreiche Funktionalitäten erweitern.
Diese Analogie zu Ende spinnend: Erdbeben erfolgen ausnahmslos an der Oberfläche, der harte Kern ist sehr stabil bzw. ausgereift. Doch anders als das Erd-Modell verfügt das MediaWiki über eine Versionsgeschichte, die sämtliche Änderungen der Benutzer reversibel macht. Fehleingaben werden dadurch leicht verziehen. Außerdem bleiben alte Zustände dadurch zitierfähig.
Die Möglichkeit zur Rekonstruktion alter Stände gilt übrigens nicht nur für Textinhalte. Auch Dateien können versioniert gespeichert werden. Und wie aus der Wikipedia bekannt, können Bildformate direkt sichtbar gemacht werden. Auf diese Weise läßt sich das MediaWiki ohne weiteres zur Bilddatenbank und zu einem Dokumentenmanagement erweitern.
Für die diesem Aufsatz zugrunde liegende Musterdatenbank wurde ein Datenmodell gewählt, das dem ISAD(G)-Standard sehr nahe kommt. Kleine Abweichungen sind im zusätzlichen »Darin«-Feld zu erkennen. Auch die Bilder oder Anhänge sind untypisch, zeigen aber den fließenden Übergang zur Bilddatenbank.
|

Die große Stärke des MediaWiki zeigt sich gerade dann, wenn es gilt, Datenmodelle (u. U. im laufenden Betrieb) umzubauen. Der Umstand, daß auf der »Erdkruste« und im »Erdmantel« Code und Daten miteinander verschmelzen, ermöglicht die Durchführung systemrelevanter Änderungen mit Textwerkzeugen, die sämtlich das MediaWiki selbst anbietet! So ist es problemlos möglich, Änderungen an einer großen Anzahl von Datensätzen global vorzunehmen.
Schwächen?
Bei allem Lob, es gibt natürlich auch Schwächen.
Es kann vorkommen, daß der ObjektCache im Erdkern der Aktivität im Erdmantel hinterherhinkt. Normalerweise wird dies nur nach automatisierten Schreib-Lese-Vorgängen großer Datenmengen sichtbar, weshalb die Beeinträchtigungen eher den Administrator treffen, und nicht den Anwender. Es existieren aber Hilfsmittel, um das Abarbeiten der s.g. »Job Queue« zu beschleunigen und Ansichten zu aktualisieren.
Das MediaWiki bietet einen solch reichen Kosmos an Möglichkeiten, daß dem Bearbeiter unweigerlich mehr Sachverstand abverlangt wird. Immerhin ist diese Anforderung nicht sehr speziell, schließlich bringt jeder, der sich schon an der Wikipedia beteiligt hat, diese Kenntnisse mit. Außerdem sind die Arbeitsprozesse bestens dokumentiert. Trotzdem muß der Bearbeiter die Tektonik seines Archivs kennen und z.B. bei der Vergabe von Signaturen diszipliniert arbeiten. Diese potentielle Fehlerquelle wird allerdings sehr schön dadurch kompensiert, daß in Serie eingeschlichene Fehler eines unerfahrenen Bearbeiters in der Regel über ein umfassendes Suchen&Ersetzen leicht behoben werden können. Auf dieselbe Weise lassen sich übrigens auch neue Vorgaben problemlos auf ältere Datensätze anwenden, ohne daß ein erneutes Aufrufen alter Datensätze notwendig werden würde.
Fazit
|

Zusammenfassend ist zu sagen: Das Potential des zur Datenbank gereiften MediaWiki ist enorm! Schon die Performance ist überzeugend und die Kinderkrankheiten sind bei einer Software mit solch großer Verbreitung weitestgehend ausgeheilt. Und prinzipiell kann kein proprietäres System hinsichtlich Langzeitarchivierung bieten, was ein OpenSource-System wie das MediaWiki bietet: Eine sehr günstige Zukunftsprognose, Bindungsfreiheit, die denkbar geringsten Anschaffungskosten und eine sehr gut kalkulierbare Kostenentwicklung im laufenden Betrieb.
Die Musterdatenbank der hier gezeigten Beispiele ist online einsehbar hier.
Der identische Aufsatz ist auch als PDF verfügbar hier.
Klaus Wendel - am Donnerstag, 31. Mai 2012, 23:59 - Rubrik: Archivsoftware