Erschließung
KlausGraf - am Dienstag, 5. Mai 2015, 16:40 - Rubrik: Erschließung
noch kein Kommentar - Kommentar verfassen
"Tamara Müller
Die Schwierigkeiten bei der Recherche im Archiv(-katalog) - Ursachenforschung und Vorschläge zur Problemstellung
Diese Arbeit setzt sich mit der Recherche in Online-Archivkatalogen auseinander. Sie ermittelt anhand empirischer erhobener Daten bei Benutzenden und Mitarbeitenden in Archiven die Art, wie gesucht wird und die Probleme, die bei der Suche nach relevanten Unterlagen auftreten.
Benutzende verwenden mehrheitlich die Volltextsuche und suchen nach Namen, Orten oder thematischen Begriffen. Die auftretenden Schwierigkeiten sind unterschiedlich und werden verschieden ausgeprägt wahrgenommen. Während die Mitarbeitenden die Bestimmung des Informationsbedarfs, mangelnde IKT-Kompetenz sowie Verwaltungs- und Archivwissen bemängeln, fehlen den Benutzenden vor allem die von ihnen gesuchten Metadaten im Archivkatalog. Hingegen erachten beide Seiten Archiverfahrung als wichtig bis sehr wichtig.
Die Lösung setzt auf mehreren Ebenen an: Einerseits reichen die aktuellen Erschliessungs-standards nicht, um bei der Recherche die benötigten Metadaten abzubilden und andererseits ist ein intensiver und regelmässiger Austausch zwischen Archiv und Benutzenden nötig. Als Drittes braucht es im Bereich der Technologie Untersuchungen wie z.B. zur Usability und Verbesserungsmassnahmen."
Die Bachelor-Arbeit, die wohl von Erfahrungen mit dem Staatsarchiv Bern ausgeht (explizit wird nicht gesagt, in welchem Archiv die Benutzer befragt wurden), steht zum kostenlosen Download bereit unter:
http://www.htwchur.ch/informationswissenschaft/forschung-und-dienstleistung/churer-schriften.html
bzw. direkt
http://www.htwchur.ch/uploads/media/CSI_74_Mueller.pdf
Die Schwierigkeiten bei der Recherche im Archiv(-katalog) - Ursachenforschung und Vorschläge zur Problemstellung
Diese Arbeit setzt sich mit der Recherche in Online-Archivkatalogen auseinander. Sie ermittelt anhand empirischer erhobener Daten bei Benutzenden und Mitarbeitenden in Archiven die Art, wie gesucht wird und die Probleme, die bei der Suche nach relevanten Unterlagen auftreten.
Benutzende verwenden mehrheitlich die Volltextsuche und suchen nach Namen, Orten oder thematischen Begriffen. Die auftretenden Schwierigkeiten sind unterschiedlich und werden verschieden ausgeprägt wahrgenommen. Während die Mitarbeitenden die Bestimmung des Informationsbedarfs, mangelnde IKT-Kompetenz sowie Verwaltungs- und Archivwissen bemängeln, fehlen den Benutzenden vor allem die von ihnen gesuchten Metadaten im Archivkatalog. Hingegen erachten beide Seiten Archiverfahrung als wichtig bis sehr wichtig.
Die Lösung setzt auf mehreren Ebenen an: Einerseits reichen die aktuellen Erschliessungs-standards nicht, um bei der Recherche die benötigten Metadaten abzubilden und andererseits ist ein intensiver und regelmässiger Austausch zwischen Archiv und Benutzenden nötig. Als Drittes braucht es im Bereich der Technologie Untersuchungen wie z.B. zur Usability und Verbesserungsmassnahmen."
Die Bachelor-Arbeit, die wohl von Erfahrungen mit dem Staatsarchiv Bern ausgeht (explizit wird nicht gesagt, in welchem Archiv die Benutzer befragt wurden), steht zum kostenlosen Download bereit unter:
http://www.htwchur.ch/informationswissenschaft/forschung-und-dienstleistung/churer-schriften.html
bzw. direkt
http://www.htwchur.ch/uploads/media/CSI_74_Mueller.pdf
KlausGraf - am Freitag, 1. Mai 2015, 16:49 - Rubrik: Erschließung
noch kein Kommentar - Kommentar verfassen
http://www.kreisarchiv-lrasha.findbuch.net/php/main.php?ar_id=3707
Via
http://www.swp.de/schwaebisch_hall/lokales/schwaebisch_hall/art1188139,3026013
Via
http://www.swp.de/schwaebisch_hall/lokales/schwaebisch_hall/art1188139,3026013
KlausGraf - am Donnerstag, 2. April 2015, 23:32 - Rubrik: Erschließung
noch kein Kommentar - Kommentar verfassen
Am 26. März wurde das Onlineportal
https://portal.ehri-project.eu/
präsentiert:
http://www.ehri-project.eu/online-portal-connects-holocaust-archives-worldwide
EHRI bietet Informationen über Archivmaterial nicht nur zum Holocaust, sondern aus der Zeit des Nationalsozialismus insgesamt, aus dem Zweiten Weltkrieg, auch aus der Nachkriegszeit, das in Institutionen in Europa und weltweit verwahrt wird, möchte transnationale und vergleichende Forschungsansätze unterstützen. Die unten beschriebenen Inhalte sind derzeit erst teilw. ausgeführt, ansonsten für die weitere Bearbeitung als Schema angelegt. Laut "about" werden aber kontinuierlich neue Informationen und Funktionen hinzugefügt:
https://portal.ehri-project.eu/about
EHRI gliedert sich in drei Rubriken jew. mit Zugriff über Listen und durch Volltextsuche:
1. 57 Länderberichte, beinhalten, sowweit bereits ausgeführt, einen kurzen Abriß der Geschichte, einen Bericht über bereits vorhandene Archivführer und die Archivsituation, eine Liste bestandsführender Archive, Hinweise auf die wichtigsten relevanten Archive.
2. Beschreibungen von insges. 1 828 Archiven in 51 Ländern, Zugang auch über die Länderberichte. Jew. eine kurze Archivgeschichte, Bestandsbeschreibungen, Links zu Findmitteln und Veröffentlichungen, Hinweis auf Zugangs- und Nutzungsbestimmungen, Verzeichnungsgrundsätze.
3. 152 672 Bestandsbeschreibungen von 464 Institutionen, optional Vorauswahl nach Sprache. Bei meiner Testsuche nach "bibliotheken"
https://portal.ehri-project.eu/units?q=bibliotheken&lang=deu
finde ich, dass ein Teil der Einträge mit einem Navigationspfad versehen ist; zwei Beispiele:
Eichmann-Prozess: Institut für Zeitgeschichte–Archiv / Gerichtsakten / Internationale u. ausländische Gerichtsorte / Israel (Eichmann-Prozess)
Tätigkeit Helene Webers auf parlamentarischem Gebiet: Institut für Zeitgeschichte–Archiv / Nachlässe / Weber, Helene / Parlamentarisch / Zonenbeirat
https://portal.ehri-project.eu/
präsentiert:
http://www.ehri-project.eu/online-portal-connects-holocaust-archives-worldwide
EHRI bietet Informationen über Archivmaterial nicht nur zum Holocaust, sondern aus der Zeit des Nationalsozialismus insgesamt, aus dem Zweiten Weltkrieg, auch aus der Nachkriegszeit, das in Institutionen in Europa und weltweit verwahrt wird, möchte transnationale und vergleichende Forschungsansätze unterstützen. Die unten beschriebenen Inhalte sind derzeit erst teilw. ausgeführt, ansonsten für die weitere Bearbeitung als Schema angelegt. Laut "about" werden aber kontinuierlich neue Informationen und Funktionen hinzugefügt:
https://portal.ehri-project.eu/about
EHRI gliedert sich in drei Rubriken jew. mit Zugriff über Listen und durch Volltextsuche:
1. 57 Länderberichte, beinhalten, sowweit bereits ausgeführt, einen kurzen Abriß der Geschichte, einen Bericht über bereits vorhandene Archivführer und die Archivsituation, eine Liste bestandsführender Archive, Hinweise auf die wichtigsten relevanten Archive.
2. Beschreibungen von insges. 1 828 Archiven in 51 Ländern, Zugang auch über die Länderberichte. Jew. eine kurze Archivgeschichte, Bestandsbeschreibungen, Links zu Findmitteln und Veröffentlichungen, Hinweis auf Zugangs- und Nutzungsbestimmungen, Verzeichnungsgrundsätze.
3. 152 672 Bestandsbeschreibungen von 464 Institutionen, optional Vorauswahl nach Sprache. Bei meiner Testsuche nach "bibliotheken"
https://portal.ehri-project.eu/units?q=bibliotheken&lang=deu
finde ich, dass ein Teil der Einträge mit einem Navigationspfad versehen ist; zwei Beispiele:
Eichmann-Prozess: Institut für Zeitgeschichte–Archiv / Gerichtsakten / Internationale u. ausländische Gerichtsorte / Israel (Eichmann-Prozess)
Tätigkeit Helene Webers auf parlamentarischem Gebiet: Institut für Zeitgeschichte–Archiv / Nachlässe / Weber, Helene / Parlamentarisch / Zonenbeirat
IngridStrauch - am Sonntag, 29. März 2015, 18:17 - Rubrik: Erschließung
noch kein Kommentar - Kommentar verfassen
Nicht nur die Bemerkung von Falk Eisermann,
http://archiv.twoday.net/stories/1022406587/#1022407938
auch eigene Erfahrungen mit Findmitteln lassen es geraten erscheinen, die folgenden Empfehlungen zur Diskussion zu stellen.
1. Besteht eine Verzeichnungseinheit aus einer oder mehreren Druckschriften, so ist dies eindeutig kenntlich zu machen. Vorgeschlagen wird die einheitliche Bezeichnung "Druckschrift" bzw. "Druckschriften", um sie bei einer Volltextsuche auffinden zu können.
Handelt es sich lediglich um vorgedruckte Formulare aus der Zeit aus dem 18. Jahrhundert, die handschriftlich ausgefüllt wurden oder werden sollten, kann der Hinweis entfallen. Dies gilt auch für sogenannte "Ephemera"/Kleindrucksachen.
http://de.wikipedia.org/wiki/Ephemera
2. Befinden sich Druckschriften in einer Verzeichnungseinheit, so ist in einem Enthält- oder Darin-Vermerk auf diese - analog zu Punkt 1 - aufmerksam zu machen.
3. Es wird dringend empfohlen, die Erschließung durch Wiedergabe der bibliographischen Daten in Anlehnung an bibliothekarische Standards (Autor, Titel - ggf. abgekürzt -, Druckort, Erscheinungsjahr) für alle Druckschriften vorzunehmen. Die Existenz von Illustrationen sollte vermerkt werden.
Falls die Archivbibliothek fachbibliothekarisch betreut wird und/oder einem Verbundkatalog angeschlossen ist, wäre es wünschenswert, im dortigen OPAC zu katalogisieren.
4. Handelt es sich nicht um gängige Werke, sollte in jedem Fall eine Recherche im Karlsruher Virtuellen Katalog im Findmittel dokumentiert werden, sofern dort keine oder nur wenige Nachweise zu finden sind.
http://www.ubka.uni-karlsruhe.de/kvk.html
Dies betrifft auch Drucke des 19./20. Jahrhunderts. Nicht selten verbergen sich in Archivgut Druckschriften, die sonst nirgends nachweisbar sind. In solchen Fällen genügt es nicht, den Umstand im Findmittel, das häufig Teil des "Deep Web" ist, das von den Suchmaschinen nicht berücksichtigt wird, zu dokumentieren.
5. Bei Inkunabeln (bis 31. Dezember 1500 erschienene Drucke) ist in jedem Fall Kontakt aufzunehmen mit dem Gesamtkatalog der Wiegendrucke:
gw@sbb.spk-berlin.de
http://staatsbibliothek-berlin.de/die-staatsbibliothek/abteilungen/handschriften/inkunabeln-wiegendrucke/
6. Bei sonst nicht oder nur in wenigen Exemplaren nachweisbaren Drucken sollte mit den entsprechenden Stellen, die für die bibliographische Verzeichnung zuständig sind, Kontakt aufgenommen werden.
Beispiel: VD 16 für Drucke des 16. Jahrhunderts aus dem deutschen Sprachraum
https://www.bsb-muenchen.de/index.php?id=1681&type=0
7. Ermittelte bibliographische Nachweise (GW, VD 16, VD 17, VD 18 usw.) sind der Titelaufnahme beizufügen.
8. Unikale oder sehr seltene Druckschriften sollten in Digitalisierungsprojekte des Archivs aufgenommen und Open Access im Internet präsentiert werden. Eine Zusammenarbeit mit bibliothekarischen Digitalisierungsprojekten ist anzustreben.
Siehe etwa zu den Druckschriften des 17. Jahrhunderts im estnischen Staatsarchiv:
http://www.ra.ee/plakatid/index.php/de

http://archiv.twoday.net/stories/1022406587/#1022407938
auch eigene Erfahrungen mit Findmitteln lassen es geraten erscheinen, die folgenden Empfehlungen zur Diskussion zu stellen.
1. Besteht eine Verzeichnungseinheit aus einer oder mehreren Druckschriften, so ist dies eindeutig kenntlich zu machen. Vorgeschlagen wird die einheitliche Bezeichnung "Druckschrift" bzw. "Druckschriften", um sie bei einer Volltextsuche auffinden zu können.
Handelt es sich lediglich um vorgedruckte Formulare aus der Zeit aus dem 18. Jahrhundert, die handschriftlich ausgefüllt wurden oder werden sollten, kann der Hinweis entfallen. Dies gilt auch für sogenannte "Ephemera"/Kleindrucksachen.
http://de.wikipedia.org/wiki/Ephemera
2. Befinden sich Druckschriften in einer Verzeichnungseinheit, so ist in einem Enthält- oder Darin-Vermerk auf diese - analog zu Punkt 1 - aufmerksam zu machen.
3. Es wird dringend empfohlen, die Erschließung durch Wiedergabe der bibliographischen Daten in Anlehnung an bibliothekarische Standards (Autor, Titel - ggf. abgekürzt -, Druckort, Erscheinungsjahr) für alle Druckschriften vorzunehmen. Die Existenz von Illustrationen sollte vermerkt werden.
Falls die Archivbibliothek fachbibliothekarisch betreut wird und/oder einem Verbundkatalog angeschlossen ist, wäre es wünschenswert, im dortigen OPAC zu katalogisieren.
4. Handelt es sich nicht um gängige Werke, sollte in jedem Fall eine Recherche im Karlsruher Virtuellen Katalog im Findmittel dokumentiert werden, sofern dort keine oder nur wenige Nachweise zu finden sind.
http://www.ubka.uni-karlsruhe.de/kvk.html
Dies betrifft auch Drucke des 19./20. Jahrhunderts. Nicht selten verbergen sich in Archivgut Druckschriften, die sonst nirgends nachweisbar sind. In solchen Fällen genügt es nicht, den Umstand im Findmittel, das häufig Teil des "Deep Web" ist, das von den Suchmaschinen nicht berücksichtigt wird, zu dokumentieren.
5. Bei Inkunabeln (bis 31. Dezember 1500 erschienene Drucke) ist in jedem Fall Kontakt aufzunehmen mit dem Gesamtkatalog der Wiegendrucke:
gw@sbb.spk-berlin.de
http://staatsbibliothek-berlin.de/die-staatsbibliothek/abteilungen/handschriften/inkunabeln-wiegendrucke/
6. Bei sonst nicht oder nur in wenigen Exemplaren nachweisbaren Drucken sollte mit den entsprechenden Stellen, die für die bibliographische Verzeichnung zuständig sind, Kontakt aufgenommen werden.
Beispiel: VD 16 für Drucke des 16. Jahrhunderts aus dem deutschen Sprachraum
https://www.bsb-muenchen.de/index.php?id=1681&type=0
7. Ermittelte bibliographische Nachweise (GW, VD 16, VD 17, VD 18 usw.) sind der Titelaufnahme beizufügen.
8. Unikale oder sehr seltene Druckschriften sollten in Digitalisierungsprojekte des Archivs aufgenommen und Open Access im Internet präsentiert werden. Eine Zusammenarbeit mit bibliothekarischen Digitalisierungsprojekten ist anzustreben.
Siehe etwa zu den Druckschriften des 17. Jahrhunderts im estnischen Staatsarchiv:
http://www.ra.ee/plakatid/index.php/de
KlausGraf - am Dienstag, 17. März 2015, 16:53 - Rubrik: Erschließung
noch kein Kommentar - Kommentar verfassen
Wenn der Server nicht gerade down ist oder sonst etwas ist (derzeit sind die PDF-Findmittel nicht mehr erreichbar), kann man in der Theorie einen Versuch unternehmen, in den Online-Findmitteln der Staatlichen Archive Bayerns etwas zu finden. Etwa in der Findmitteldatenbank.
Dass dort jeder Eintrag mit einem URN versehen ist, den man anders als in den meisten Bibliotheksanwendungen nicht anklicken kann, soll wohl vortäuschen, dass ein dauerhafter Zugriff unter diesem URN möglich ist (andernorts als Permalinks bekannt). Die wenigsten werden die Mühe auf sich nehmen, unter
http://nbn-resolving.de/
nachzuschauen, ob die URNs auch funktionieren. DAS IST IN DER REGEL NICHT DER FALL!
StAA, Fürststift Kempten, Archiv Akten 2403
The URN urn:nbn:de:stab-a99d1cac-e601-48d4-9a55-39645e501cf29 is not registered at the German National Library
StAN Rst. Nürnberg, Päpstliche und fürstliche Privilegien, Urkunden 247
The URN urn:nbn:de:stab-6a1d8c5a-df77-4d43-b4d1-ade9334668320 is not registered at the German National Library
BayHStA, Bayern Urkunden 4234/ d
The URN urn:nbn:de:stab-58b38f00-e329-4817-bf3e-691b08d175dd2 is not registered at the German National Library
Ich kann nicht abschätzen, welcher Anteil von URNs nicht registriert ist, aber nach meinen bisherigen Erfahrungen, sind es sehr viele.
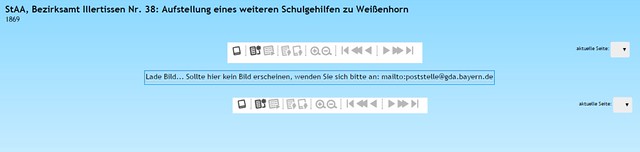
Hat man aber diese Hürde genommen, so bedeutet das nicht, dass die Weiterleitung des NBN-Resolvers auf eine sinnvolle Internetadresse erfolgt. Man sieht dann anscheinend immer nur einen Viewer, der das Laden eines Bilds ankündigt. Es lädt aber kein Bild, was bei einem einfachen Findbucheintrag ja auch nicht nötig ist.
Liebe GDA, Euer verantwortungsloses Treiben beschädigt das Vertrauen in die Nutzung von Persistent Identifyer im Archivbereich. URNs sind kein Spielzeug, mit dem man arglose Anwender erst einmal monatelang in die Irre schickt.
Dass dort jeder Eintrag mit einem URN versehen ist, den man anders als in den meisten Bibliotheksanwendungen nicht anklicken kann, soll wohl vortäuschen, dass ein dauerhafter Zugriff unter diesem URN möglich ist (andernorts als Permalinks bekannt). Die wenigsten werden die Mühe auf sich nehmen, unter
http://nbn-resolving.de/
nachzuschauen, ob die URNs auch funktionieren. DAS IST IN DER REGEL NICHT DER FALL!
StAA, Fürststift Kempten, Archiv Akten 2403
The URN urn:nbn:de:stab-a99d1cac-e601-48d4-9a55-39645e501cf29 is not registered at the German National Library
StAN Rst. Nürnberg, Päpstliche und fürstliche Privilegien, Urkunden 247
The URN urn:nbn:de:stab-6a1d8c5a-df77-4d43-b4d1-ade9334668320 is not registered at the German National Library
BayHStA, Bayern Urkunden 4234/ d
The URN urn:nbn:de:stab-58b38f00-e329-4817-bf3e-691b08d175dd2 is not registered at the German National Library
Ich kann nicht abschätzen, welcher Anteil von URNs nicht registriert ist, aber nach meinen bisherigen Erfahrungen, sind es sehr viele.
Hat man aber diese Hürde genommen, so bedeutet das nicht, dass die Weiterleitung des NBN-Resolvers auf eine sinnvolle Internetadresse erfolgt. Man sieht dann anscheinend immer nur einen Viewer, der das Laden eines Bilds ankündigt. Es lädt aber kein Bild, was bei einem einfachen Findbucheintrag ja auch nicht nötig ist.
Liebe GDA, Euer verantwortungsloses Treiben beschädigt das Vertrauen in die Nutzung von Persistent Identifyer im Archivbereich. URNs sind kein Spielzeug, mit dem man arglose Anwender erst einmal monatelang in die Irre schickt.
KlausGraf - am Samstag, 14. März 2015, 16:27 - Rubrik: Erschließung
http://arkiv.dk/
So sollte man es nicht machen. Eine nur auf Dänisch verfügbare Metasuche, bei der die Digitalisate in geringer Auflösung und nur mit einem scheußlichen Wasserzeichen zur Verfügung stehen. Für das öffentliche Teilen ist nur Facebook vorgesehen, anders als bei der DDB gibt es anscheinend keine CC-Lizenzen. Ob der Link in der Adresszeile wohl ein Permalink ist?
Via
http://cphpost.dk/news/denmarks-largest-digital-archive-opens-today.12735.html
Weitere archivische Metasuchen:
http://archiv.twoday.net/stories/6424341/
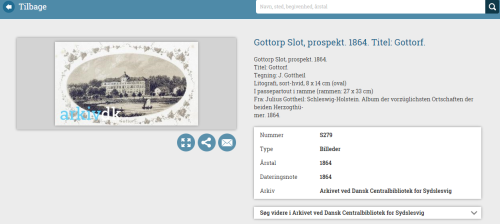
So sollte man es nicht machen. Eine nur auf Dänisch verfügbare Metasuche, bei der die Digitalisate in geringer Auflösung und nur mit einem scheußlichen Wasserzeichen zur Verfügung stehen. Für das öffentliche Teilen ist nur Facebook vorgesehen, anders als bei der DDB gibt es anscheinend keine CC-Lizenzen. Ob der Link in der Adresszeile wohl ein Permalink ist?
Via
http://cphpost.dk/news/denmarks-largest-digital-archive-opens-today.12735.html
Weitere archivische Metasuchen:
http://archiv.twoday.net/stories/6424341/
KlausGraf - am Samstag, 21. Februar 2015, 13:28 - Rubrik: Erschließung
noch kein Kommentar - Kommentar verfassen
Spitze Klammern aus XML wurden als geschweifte dargestellt, um Browser hinsichtlich der Darstellung am Bildschirm nicht zu verwirren!
Ausgangssituation:
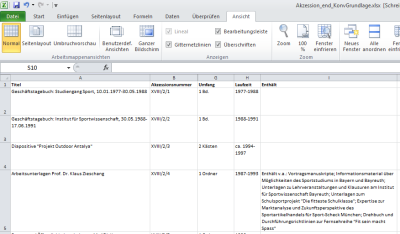
1. Ihre Excel-Tabelle enthält Erschließungsinformationen in einer Spaltenaufteilung, die den Anforderungen von EAD bzw. ISAD(G) entsprechen (=Gliederung nach den üblichen Verzeichnungsfelder).
2. Die Erschließungsinformationen gehören derselben Verzeichnungsstufe an. (Die Konvertierung in unterschiedlichen Verzeichnungsstufen wäre deutlich aufwendiger!)
3. Oberhalb der Spaltenüberschriften befinden sich keine weiteren Felder.
Konvertierungsvorgang:
1. Legen Sie für sich fest, welche Spalte mit welchem EAD-Tag kodiert werden soll. Nur in wenigen Fällen werden dabei Wahlmöglichkeiten bestehen (z.B. Titel als {unittitle}, Enhältvermerk als {abstract} usw.). Verwenden Sie dabei die EAD-Tags, die Ihre Archivsoftware für die Kodierung der jeweiligen Art von Information verwendet, damit Ihre Software das Konvertierungsergebnis später lesen kann! Es ist hilfreich, sich eine bereits existierende EAD-XML-Datei anzuschauen bzw. auszudrucken, um zu sehen, was für ein EAD-Profil die Software verwendet.
2. Erstellen Sie ein Worddokument und schreiben den vollständigen EAD-Kode für einen einzigen Datensatz (= für eine Zeile der Exceltabelle).
Dies kann z.B. so aussehen:
{c02 level=“file“}
{did}
{physdesc}
{extent}{/extent}
{physdesc}
{unitid type=”bestellnummer”}{/unitid}
{unittitle}{/unittitle}
{unitdate}{/unitdate}
{abstract}{/abstract}
{/did}
{/c02}
3. Starten Sie die Seriendruckfunktion in Word und geben Sie an, ein „Verzeichnis“ (in älteren Wordversionen „Katalog“) erstellen zu wollen. Wählen Sie Ihre Exceltabelle als Quelldatei aus. Fügen Sie nun zwischen Anfang und Ende der EAD-Tags mittels „Seriendruckfeld einfügen“ die betreffenden Verweise auf die Spalten Ihrer Exceltabelle ein.
4. Erzeugen Sie nun die Seriendruckdatei über „Fertig stellen und zusammenführen“.
5. Speichern Sie die erzeugte Datei als TXT-Datei ab.
6. Öffnen sie diese Datei mit einem Editor, z.B. Notepad++ und ersetzen Sie die Anführungs- und Schlusszeichen durch Anführungs- und Schlusszeichen. Der Editor wird dabei Spezifika der Word-generierten Zeichen beseitigen und diese Zeichen standardisieren. Anschließend speichern Sie die Datei als XML ab.
7. Erzeugen Sie nun mit Ihrer Archivsoftware eine neue Findbuchdatei. Ihre Tektonik soll bis dahin reichen, wo Sie die neuen Verzeichnungseinheiten einfügen wollen.
8. Öffnen Sie die mit der Archivsoftware erzeugte Datei mit einem Editor (z.B. Notepad++). Eventuell müssen Sie dazu vorübergehend die Dateiendung in .xml verändern. Kopieren Sie die komplette XML-Datei, die die Erschließungsinformation aus der Excel-Tabelle enthält, und fügen Sie sie in die Datei aus der Archivsoftware oberhalb der folgenden letzten Zeilen ein:
{/c01}
{/dsc}
{/archdesc}
{/ead}
Speichern Sie die Datei als XML ab.
Sofern die Datei inhaltlich und in ihrer Tektonik so bereits Ihren Wünschen entspricht, können Sie sie jetzt bereits auch außerhalb Ihrer Archivsoftware weiterverwenden (z.B. als Input in ein Archivportal).
9. Fertigen Sie ggf. eine Kopie der Datei an und ändern die Endung .xml wieder so, wie sie von Ihrer Archivsoftware ursprünglich erzeugt wurde (bei MidosaXML z.B. in die Endung .ead).
10. Öffnen Sie die Datei mit Ihrer Archivsoftware und bearbeiten Sie sie in Inhalt und Struktur beliebig weiter.
Ausgangssituation:
1. Ihre Excel-Tabelle enthält Erschließungsinformationen in einer Spaltenaufteilung, die den Anforderungen von EAD bzw. ISAD(G) entsprechen (=Gliederung nach den üblichen Verzeichnungsfelder).
2. Die Erschließungsinformationen gehören derselben Verzeichnungsstufe an. (Die Konvertierung in unterschiedlichen Verzeichnungsstufen wäre deutlich aufwendiger!)
3. Oberhalb der Spaltenüberschriften befinden sich keine weiteren Felder.
Konvertierungsvorgang:
1. Legen Sie für sich fest, welche Spalte mit welchem EAD-Tag kodiert werden soll. Nur in wenigen Fällen werden dabei Wahlmöglichkeiten bestehen (z.B. Titel als {unittitle}, Enhältvermerk als {abstract} usw.). Verwenden Sie dabei die EAD-Tags, die Ihre Archivsoftware für die Kodierung der jeweiligen Art von Information verwendet, damit Ihre Software das Konvertierungsergebnis später lesen kann! Es ist hilfreich, sich eine bereits existierende EAD-XML-Datei anzuschauen bzw. auszudrucken, um zu sehen, was für ein EAD-Profil die Software verwendet.
2. Erstellen Sie ein Worddokument und schreiben den vollständigen EAD-Kode für einen einzigen Datensatz (= für eine Zeile der Exceltabelle).
Dies kann z.B. so aussehen:
{c02 level=“file“}
{did}
{physdesc}
{extent}{/extent}
{physdesc}
{unitid type=”bestellnummer”}{/unitid}
{unittitle}{/unittitle}
{unitdate}{/unitdate}
{abstract}{/abstract}
{/did}
{/c02}
3. Starten Sie die Seriendruckfunktion in Word und geben Sie an, ein „Verzeichnis“ (in älteren Wordversionen „Katalog“) erstellen zu wollen. Wählen Sie Ihre Exceltabelle als Quelldatei aus. Fügen Sie nun zwischen Anfang und Ende der EAD-Tags mittels „Seriendruckfeld einfügen“ die betreffenden Verweise auf die Spalten Ihrer Exceltabelle ein.
4. Erzeugen Sie nun die Seriendruckdatei über „Fertig stellen und zusammenführen“.
5. Speichern Sie die erzeugte Datei als TXT-Datei ab.
6. Öffnen sie diese Datei mit einem Editor, z.B. Notepad++ und ersetzen Sie die Anführungs- und Schlusszeichen durch Anführungs- und Schlusszeichen. Der Editor wird dabei Spezifika der Word-generierten Zeichen beseitigen und diese Zeichen standardisieren. Anschließend speichern Sie die Datei als XML ab.
7. Erzeugen Sie nun mit Ihrer Archivsoftware eine neue Findbuchdatei. Ihre Tektonik soll bis dahin reichen, wo Sie die neuen Verzeichnungseinheiten einfügen wollen.
8. Öffnen Sie die mit der Archivsoftware erzeugte Datei mit einem Editor (z.B. Notepad++). Eventuell müssen Sie dazu vorübergehend die Dateiendung in .xml verändern. Kopieren Sie die komplette XML-Datei, die die Erschließungsinformation aus der Excel-Tabelle enthält, und fügen Sie sie in die Datei aus der Archivsoftware oberhalb der folgenden letzten Zeilen ein:
{/c01}
{/dsc}
{/archdesc}
{/ead}
Speichern Sie die Datei als XML ab.
Sofern die Datei inhaltlich und in ihrer Tektonik so bereits Ihren Wünschen entspricht, können Sie sie jetzt bereits auch außerhalb Ihrer Archivsoftware weiterverwenden (z.B. als Input in ein Archivportal).
9. Fertigen Sie ggf. eine Kopie der Datei an und ändern die Endung .xml wieder so, wie sie von Ihrer Archivsoftware ursprünglich erzeugt wurde (bei MidosaXML z.B. in die Endung .ead).
10. Öffnen Sie die Datei mit Ihrer Archivsoftware und bearbeiten Sie sie in Inhalt und Struktur beliebig weiter.
Kühnel Karsten - am Montag, 3. November 2014, 16:07 - Rubrik: Erschließung
So sieht es auf einem neueren iPad aus:
https://twitter.com/ddbkultur/status/514910859580432386
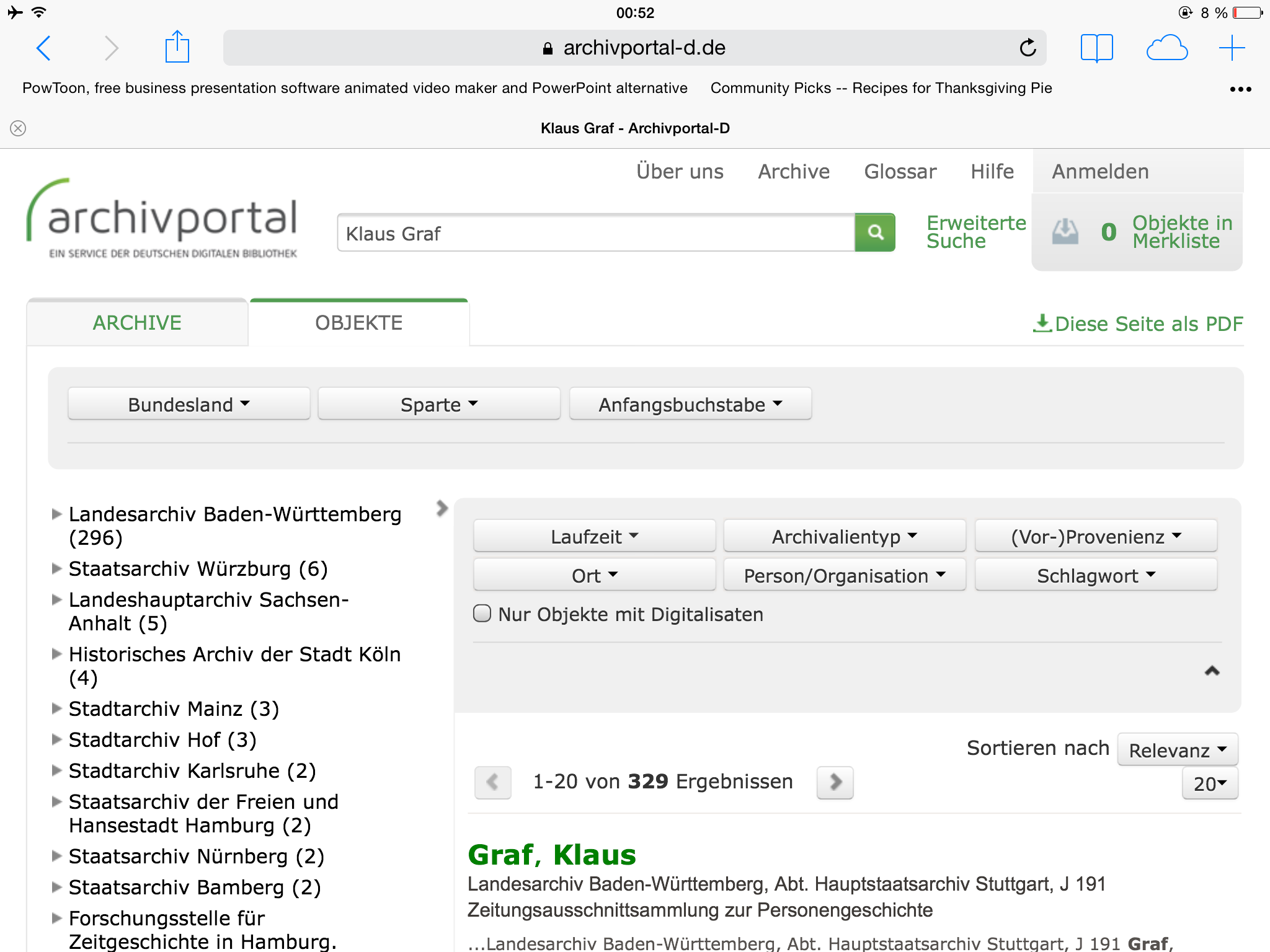
So sieht es auf meinem iPad 1 mit iOS 5 und Chrome aus:
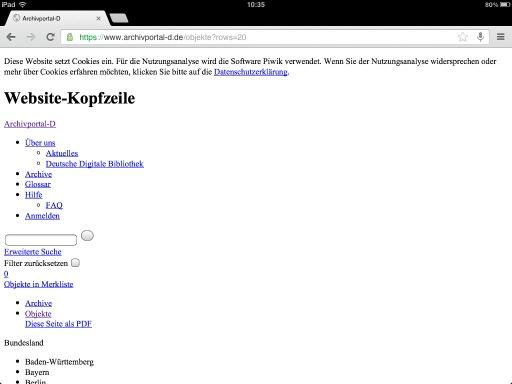
Und zwar nach dem von der DDB empfohlenen Cache-Löschen in Chrome. Und bei Safari sieht es auf meinem iPad genauso indiskutabel aus!
Eine Kurzbesprechung
http://www.blog.pommerscher-greif.de/archivportal-d/
bemängelt die Copyfraud-Hinweise einiger Archive.
Update: Alle Permalinks funktionieren nicht!
Beispiel:
http://localhost:8021/item/RJSEYW2UUCQUZJARLL2AQSU7UM56I4VX
https://twitter.com/ddbkultur/status/514910859580432386
So sieht es auf meinem iPad 1 mit iOS 5 und Chrome aus:
Und zwar nach dem von der DDB empfohlenen Cache-Löschen in Chrome. Und bei Safari sieht es auf meinem iPad genauso indiskutabel aus!
Eine Kurzbesprechung
http://www.blog.pommerscher-greif.de/archivportal-d/
bemängelt die Copyfraud-Hinweise einiger Archive.
Update: Alle Permalinks funktionieren nicht!
Beispiel:
http://localhost:8021/item/RJSEYW2UUCQUZJARLL2AQSU7UM56I4VX
KlausGraf - am Sonntag, 28. September 2014, 16:45 - Rubrik: Erschließung
KlausGraf - am Donnerstag, 25. September 2014, 08:47 - Rubrik: Erschließung